技能训练
(1)说一说信息熵、条件熵、信息增益及信息增益比的含义?
(2)谈一谈决策树算法ID3、C4.5、CART 的优点?
(3)决策树大数据算法,主要是ID3 算法操作实践。
① 作业目的:
a. 理解决策树算法原理,并掌握决策树算法框架;
b. 理解决策树学习算法的特征选择、树的生成和树的剪枝;
c. 能根据不同的数据类型,选择不同的决策树算法;
d. 针对特定应用场景及数据,能应用决策树算法解决实际问题。
② 作业准备:
Orange3 软件下载 并安装。
并安装。
并安装。 Iris(鸢尾属植物)数据集下载采用Orange3 平台自带数据库。见下图。
ID3 算法是最经典的决策树分类算法。ID3 算法基于信息熵来选择最佳的测试属性,它
选择当前样本集中具有最大信息增益值的属性作为测试属性;样本集的划分则依据测试属性
的取值进行,测试属性有多少个不同的取值就将样本集划分为多少个子样本集,同时决策树
上相对于该样本集的节点长出新的叶子节点。ID3 算法根据信息论的理论,采用划分后样本
集的不确定性作为衡量划分好坏的标准,用信息增益值度量不确定性:信息增益值越大,不
确定性越小。因此,ID3 算法在每个非叶节点选择信息增益最大的属性作为测试属性,这样
可以得到当前情况下最纯的划分,从而得到较小的决策树。
ID3 算法的具体流程如下:
a. 对当前样本集合,计算所有属性的信息增益;
b. 选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划为同一个子样
本集;
c. 若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相
应的符号,然后返回调用处;否则对子样本集递归调用本算法。
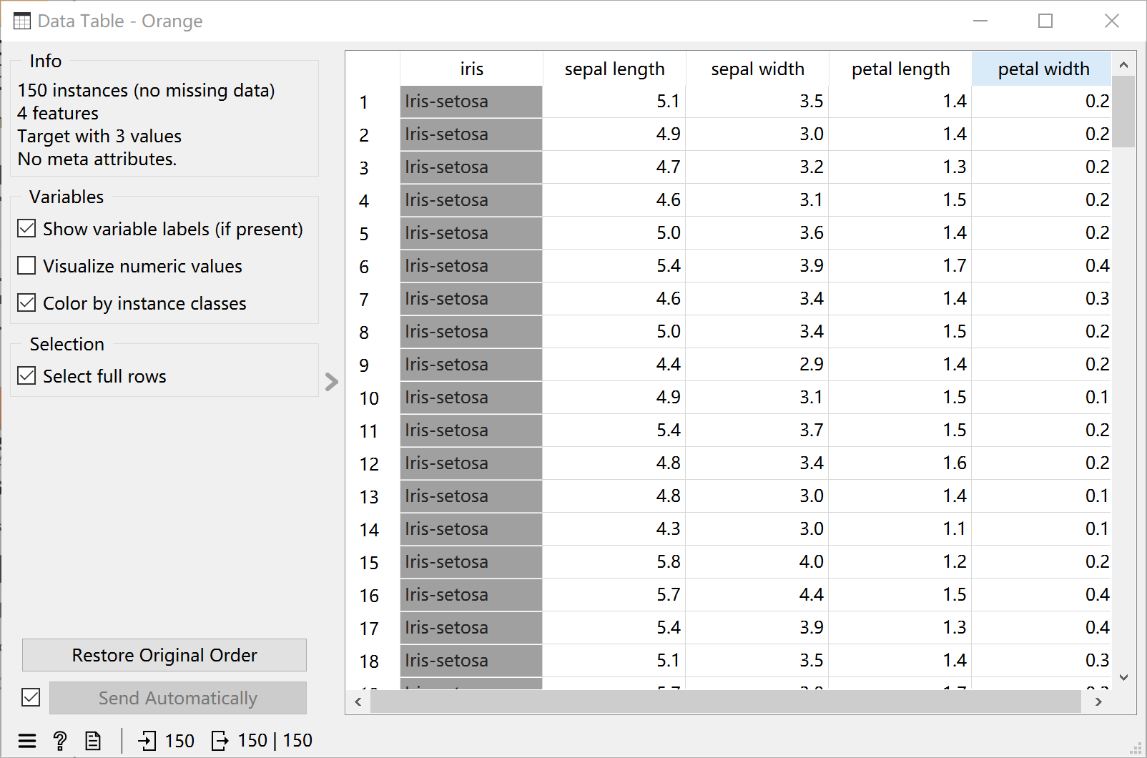
数据集说明:Iris 数据集包含150 个样本,对应数据集的每行数据。每行数据包含每个
样本的四个特征和样本的类别信息,所以Iris 数据集是一个150 行5 列的二维表。通俗地说,
Iris 数据集是用来给花做分类的数据集,每个样本包含了sepal_length(花萼长度)、sepal_width
(花萼宽度)、petal_length(花瓣长度)、petal_width(花瓣宽度)四个特征(前4 列),如图
2-1-7 所示。因此,需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山
鸢尾、变色鸢尾还是弗吉尼亚鸢尾(这三个名词都是花的品种)。见下图。
作业任务:区分Iris Setosa(山鸢尾)及Iris Versicolour(变色鸢尾)两个种类。
③ 作业内容。
a. Part1 人工数据实践。
Step1:库函数导入;
Step2:模型训练;
Step3:数据和模型可视化;
Step4:模型预测。
b. Part2 基于Iris 数据集的分类。
Step1:库函数导入;
Step2:数据读取/载入;
Step3:数据信息简单查看;
Step4:可视化描述;
Step5:在二分类上进行训练和预测;
Step6:在三分类(多分类)上进行训练和预测。
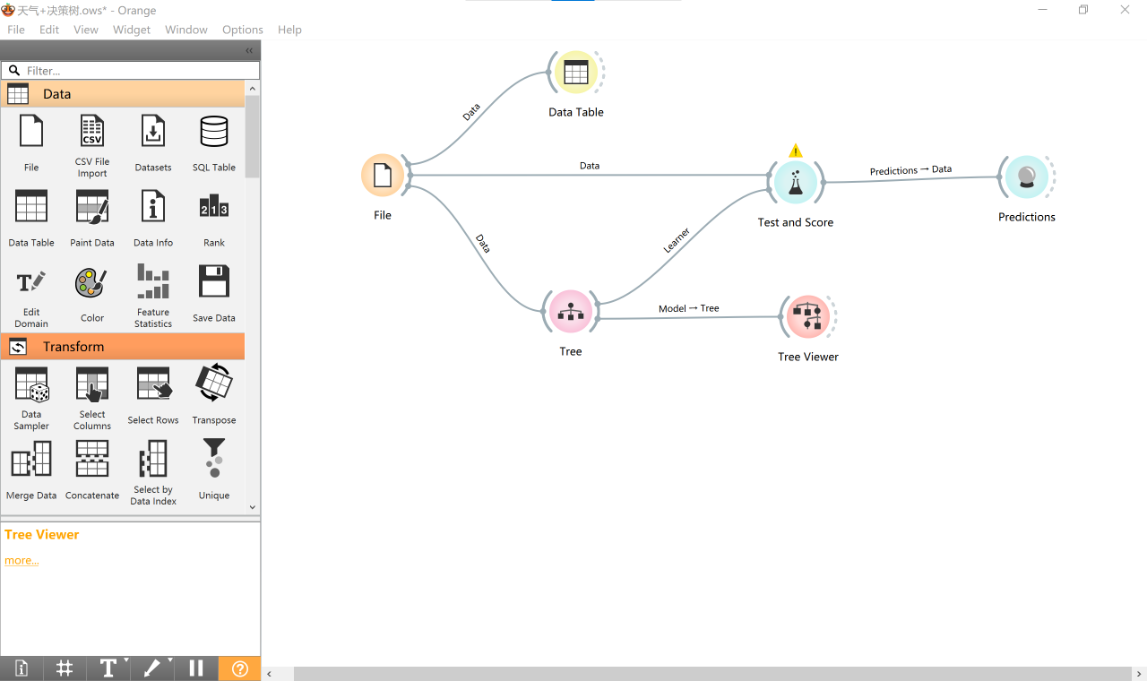
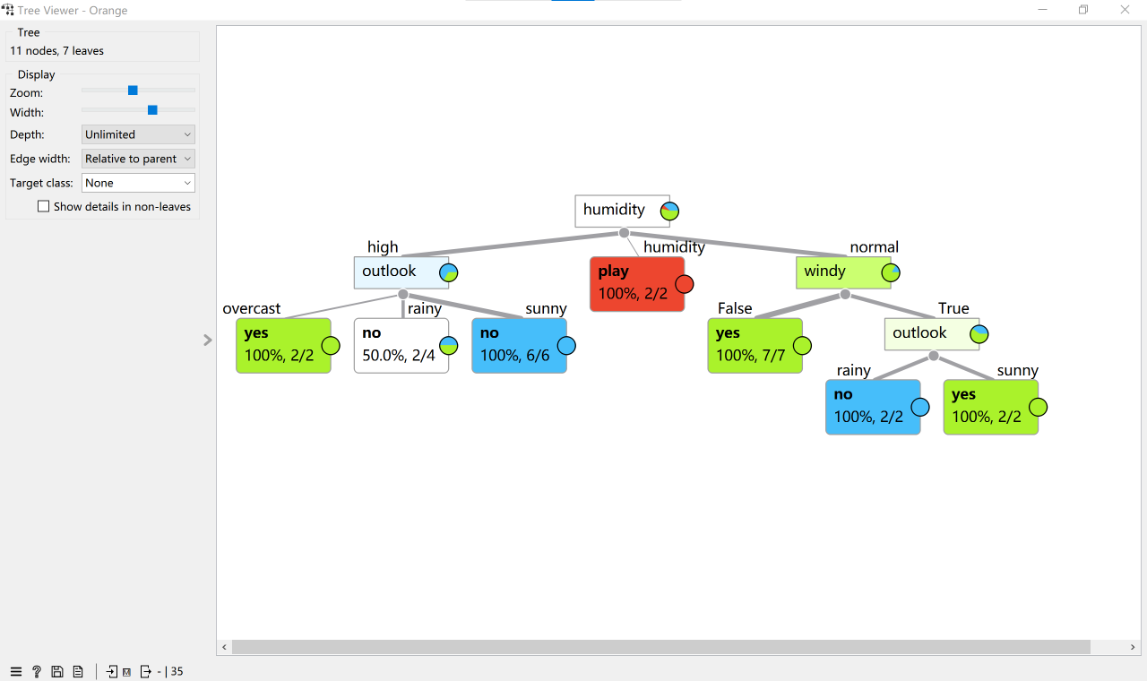
c. 决策树Orange 图示。
按照图2-1-8 生成模型评估数据。见下图。